2024. 2. 19. 17:58ㆍ논문 리뷰/NLP
Abstract
굉장히 많은 발전있던 NLP task : textual entailment, question answering, semantic similarity assessment, document classification
더 높은 성능을 위하여 여러 접근 방식 존재
1. Introduction
기존의 NLP 방식 = Supervised 방식, labeled data를 바탕으로 학습함
Natural Language Processing 이 라벨링이 된 데이터들을 바탕으로 이루어져 언어모델(LM)을 학습하였으나,
대용량의 라벨링이 된 데이터를 생성하기는 어렵기에 기존 접근 방식에 한계가 있음
-> 새로운 방식으로 Semi-Supervised 방식을 사용
2. Related Work
- Semi-supervised learning for NLP
최근 연구의 동향은 라벨링되어 있지 않은 데이터에 대하여 감성분석 및 등을 실시하려고 하고, 좀더 보다 더 높은 수준의 접근을 시도함
단어 수준에서의 접근이 아닌 Phrase, sentence 수준에서의 학습을 시도
- Unsupervised pre-training
semi-superviesed의 특수한 케이스인 Unsupervised
pre-training의 높은 성능을 이용
- Auxiliary training objectives
language의 문법 자체에 대한 학습 (POS tagging, chunking, named entity recogmition, ...)
3. Framework
training에서 어떻게 흘러가는지보면 두가지 단계로 나뉨
첫번째. large corpus에서 high-capacity language model부터 학습
두번째. 마지막으로 fine - tuning을 하게 됨(discriminative task with labeled data)
3-1. Unsupervised pre-training
가장 high-capacity language model 작성을 위하여 우도비함수를 사용하는 첫번째 단계

next word를 예측하는 확률을 바탕으로 학습을 하여 likelihood function을 작성함
word단위로 토큰화 이후에 다음 단어를 예측하는 형식을 기반으로 모델을 학습
ex. '나는 아침에 밥을 먹었다'에서 '나는 아침에 밥을'까지 입력받고 난 뒤에 다음으로 '먹었다'를 예측할 수 있도록 학습
이 과정에서 여러 레이어를 사용하는데, 이 레이어가 Transformer Decoder
encoder는 없고, decoder만 있는 관계로 cross가 아닌 self attention을 통해서만 학습을 하는 구조임

text input에서 W의 임베딩한 결과를 얻은 뒤에 transformer decoder를 적용하며, 최종적으로 softmax 함수를 사용하여 다음 단어의 확률을 내뱉음으로써 예측을 실시
3-2. Supervised fine-tuning
labeled dataset을 이용한 학습으로, 학습에서의 두번째 단계인 fine tuning
fine-tuning은 pre-training과는 다르게 Supervised를 바탕으로두는 방식임

이전 앞단계와는 다르게 y라는 label이 존재함
tokenized input data x들을 통하여 label에 대한 확률을 계산

라벨링된 데이터셋에 대한 우도비가 maximize되는 것이 이 학습모델에서의 criteria

가중치라는 패널티를 추가하여 최종적으로 완성한 language model에 대한 criteria
3-3. Task-specific input transformations
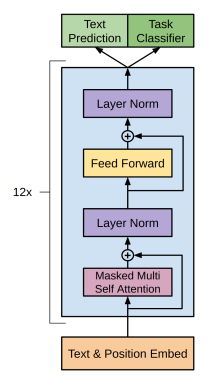
위에서 서술되었던 Transformer의 Decoder
(Transformer attention에 대한 논문 추천)
encoder가 없이 decoder의 기능만 사용하기 때문에 self-attention이 적용된다
그리고 이에 따라 fine tuning이 각각의 task에 따라서 적용이 된다
주된 NLP task : text classification / textual entailment / similarity / Question Answering and Commonsense Reasoning
- text classification

text input을 token화 -> Transformer decoder와 linear로 classification실시
- textual entailment

p(premise)와 h(hypothesis) token화 한 것을 결합(concatenate)해 처리
- Similarity

sentence를 구분자를 기준으로 token화시킨 후에 decoder를 통한 결과로 similarity 계산
- Multiple Choice

context document
question
delim($)
set of possible answers
이 단위로 token화되며 softmax를 통해 표준화됨
4. Experiments
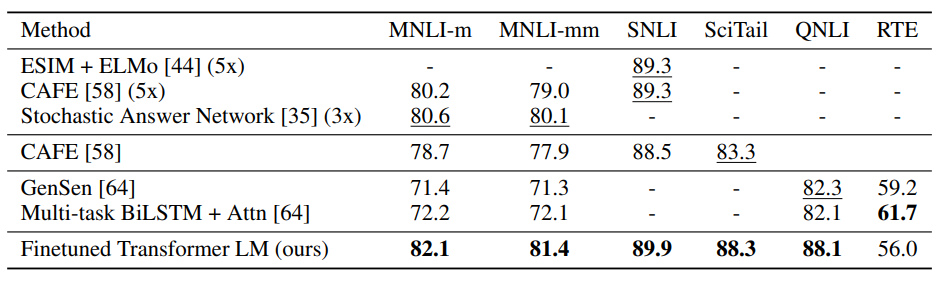
NLI task(recognizing textual entailment, judging the relationship, etc)에 대하여 Finetuned Transformer LM이 대체적으로 다른 LM보다도 높은 성능을 보이고 있음을 확인 가능

NLI task(recognizing textual entailment, judging the relationship, etc)과 Question answering and commonsense reasoning에 대하여 Finetuned Transformer LM이 대체적으로 다른 LM보다도 높은 성능을 보이고 있음을 확인 가능

그러나 Classification과 Semantic Similarity는 다른 LM들이 좀더 높은 성능을 보이는 게 많음
5. Analysis

레이어의 수가 증가할수록 더 높은 정확도를 보이는 것 확인 가능

pre-training이 강점인 것 확인 가능
(pre-training은 unsupervised)